Camping World robots.txt File SEO Mistake
The developer or SEO of the Camping World RV sub-domain has used the wrong SEO solution to deal with a duplicate content issue.
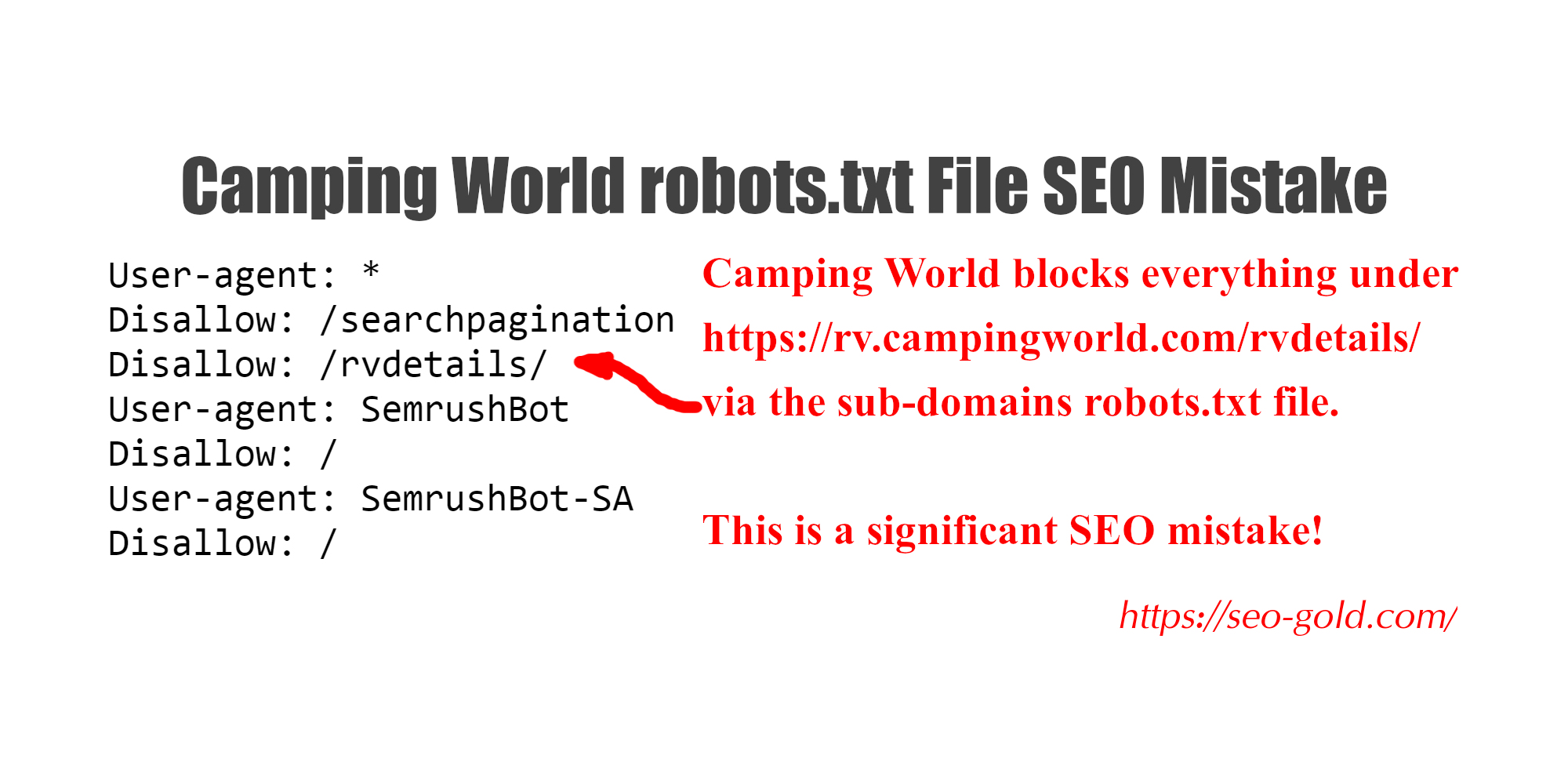
They have blocked (via the sub-domain robots.txt file https://rv.campingworld.com/robots.txt) Google from indexing one type of the Individual Product URLs which is a HUGE waste of SEO link benefit!
Content of https://rv.campingworld.com/robots.txt
User-agent: *
Disallow: /searchpagination
Disallow: /rvdetails/
User-agent: SemrushBot
Disallow: /
User-agent: SemrushBot-SA
Disallow: /
The robots.txt file code above tells various search engines how to spider/index this sub-domain.
The final 4 lines of code:
User-agent: SemrushBot
Disallow: /
User-agent: SemrushBot-SA
Disallow: /
Are requesting the search engine spiders called SemrushBot and SemrushBot-SA to NOT spider/index ANY of this sub-domain. I guess they’ve had a problem with the SEMRush spiders. This is the correct way to block a specific search engine spider. Thee are not a problem.
The first three lines however are a problem:
User-agent: *
Disallow: /searchpagination
Disallow: /rvdetails/
Line one says ALL (the wildcard * means all) search engine spiders should follow the rules below it.
Line 2 says don’t spider/index ANY URLs from this sub-domain starting with https://rv.campingworld.com/searchresults
Line 3 says don’t spider/index ANY URLs from this sub-domain starting with https://rv.campingworld.com/rvdetails/
This solves the multiple ways for Google to find the individual RV pages, but it’s the wrong solution.
The first blocking line Disallow: /searchpagination is sort of OK, there is an SEO argument NOT to block search results just so long as the output is relatively unique (I didn’t check if that was the case or not here). If we are blocking search results the robots.txt file rule above isn’t necessarily the best SEO solution, better would be to setup canonical URLs, BUT since these are search results it might not be possible, so blocking might be the only realistic SEO solution.
The second blocking line Disallow: /rvdetails/ is a major SEO problem.
The robots.txt file is blocking https://rv.campingworld.com/rvdetails/new-class-c-rvs/2020-thor-freedom-elite-22hef-rear-bath-50k-RVA1624345 which is the way most visitors AND Google will find the RV via browsing the site and searching for an RV etc… whilst allowing this page https://rv.campingworld.com/rv/1624345 (identical content to the other URL) which can only be found via a specific search (can only be found by searching for the stock number 1624345) to be indexed by Google.
The problem is Google is very likely to find the longer URL, but is less likely to find the short URL, there wasn’t an obvious click/tap route to those short URLs: how does Google find and spider them? I assume it’s via an XML sitemap.
Visitors who might like to share a link to an RV (a backlink from a blog say) are far more likely to link to the long URL (it’s much easier to find) vs the short URL (difficult to find).
This is a MAJOR SEO error.
Continue Reading Camping World RV Sales Review







